Par composition a posteriori
L'avantage de ce mode de fonctionnement est que les générations des pyramides indépendantes peuvent se faire en parallèle. Il n'y a pas de modifications de données et celles ci ne sont pas dupliquées. En revanche, une dépendance est ajoutée entre les données, ce qui va empêcher la suppression des données référencées (les pyramides utilisées dans la composition).
---
title: Étapes du tutoriel
---
stateDiagram
LIV1: Calcul de la pyramide contenant le premier jeu
note left of LIV1
Livraison (upload)
Vérification (check)
Traitement (processing)
Exécution de traitement (processing execution)
Données stockée (stored data)
end note
LIV2: Calcul de la pyramide contenant le deuxième jeu
note left of LIV2
Livraison (upload)
Vérification (check)
Traitement (processing)
Exécution de traitement (processing execution)
Données stockée (stored data)
end note
FUS: Calcul de la pyramide fusionnée
note left of FUS
Traitement (processing)
Exécution de traitement (processing execution)
Données stockée (stored data)
end note
PUB_TILED: Publication en WMTS/TMS pour validation
note right of PUB_TILED
Configuration (configuration)
Point d'accès (endpoint)
Offre (offering)
end note
state fork_state_deb <<fork>>
state fork_state_fin <<fork>>
[*] --> fork_state_deb
fork_state_deb --> LIV1
fork_state_deb --> LIV2
LIV1 --> fork_state_fin
LIV2 --> fork_state_fin
fork_state_fin --> FUS
FUS --> PUB_TILED
classDef concepts fill:#eee,stroke:#8d1d75,stroke-width:3px;
class LIV1,LIV2,PUB_TILED,FUS conceptsGestion du premier jeu de données
- Création de la livraison
/datastores/{datastore}/uploads
- Livraison des fichiers : scan1000_corse_nord.tif
- Fermeture de la livraison
- Création de l'exécution de traitement
Attention
Il est important de préciser que l'on veut générer et stocker les masques. Ces derniers vont être indispensables pour que la fusion évite la perte de données.
/datastores/{datastore}/processings/executions
- Lancement de l'exécution : ID de la données stockée
{stored data Corse Nord}
Il n'est pas nécessaire d'attendre la fin de ce traitement pour lancer celui sur le deuxième jeu.
Gestion du deuxième jeu de données
- Création de la livraison
/datastores/{datastore}/uploads
- Livraison des fichiers : scan1000_corse_sud.tif
- Fermeture de la livraison
- Création de l'exécution de traitement
Attention
Il est important de préciser que l'on veut générer et stocker les masques. Ces derniers vont être indispensables pour que la fusion évite la perte de données.
/datastores/{datastore}/processings/executions
- Lancement de l'exécution : ID de la données stockée
{stored data Corse Sud}
Génération de la pyramide fusionnée
Lorsque les deux pyramides indépendantes sont générées :
- Récupération du traitement qui nous intéresse : ID
e2220fa2-50d8-44e9-b8eb-7e6401fd8c4c
/datastores/{datastore}/processings/e2220fa2-50d8-44e9-b8eb-7e6401fd8c4c
{
"name": "Fusion de pyramides raster",
"description": "Ce traitement permet de générer une pyramide raster par composition de plusieurs pyramides indépendantes. Seules les dalles présentes dans plusieurs entrées seront recalculées. Celles présentes dans une seule entrée seront référencées. La pyramide en sortie a donc des dépendances avec celles en entrée.",
"input_types": {
"upload": [],
"stored_data": [
"ROK4-PYRAMID-RASTER"
]
},
"output_type": {
"stored_data": "ROK4-PYRAMID-RASTER",
"storage": [
"S3"
]
},
"parameters": [
{
"name": "parallelization",
"description": "Le niveau de parallélisation du calcul (nombre de scripts parallèles, nombre de threads)",
"mandatory": false,
"default_value": 1
},
{
"name": "top",
"description": "Niveau du haut de la pyramide en sortie : ce sera par défaut le plus haut de toutes les pyramides en entrée",
"mandatory": false
},
{
"name": "bottom",
"description": "Niveau du bas de la pyramide en sortie : ce sera par défaut le plus bas de toutes les pyramides en entrée",
"mandatory": false
},
{
"name": "bbox",
"description": "Étendue géographique sur laquelle sera générée la pyramide : ce sera par défaut l'union des étendues de toutes les pyramides en entrée",
"mandatory": false
}
],
"_id": "e2220fa2-50d8-44e9-b8eb-7e6401fd8c4c",
"required_checks": []
}
- Création de l'exécution de traitement (on s'appuie sur les valeurs par défaut des paramètres)
/datastores/{datastore}/processings/executions
- Lancement de l'exécution
- À la fin, on peut voir que notre nouvelle pyramide a deux dépendances : elle utilise nos deux pyramides indépendantes, qu'on ne pourra plus supprimer.
/datastores/{datastore}/stored_data/{stored data Corse}/dependencies
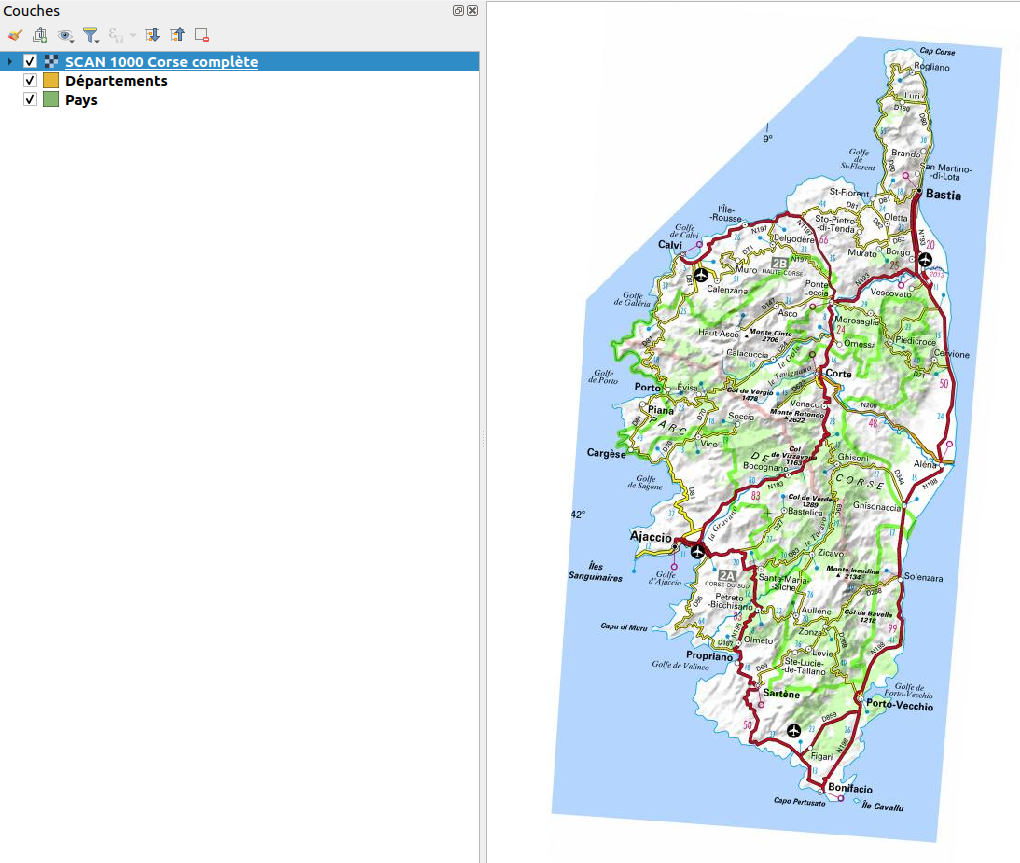
En publiant notre pyramide fusionnée, on retrouve bien la Corse en entier.